In this article, I will share my understanding on how computers identify objects (Object classification) from images using deep learning. This article is from a birds eye view. I will continue to share more detailed views on various components involved in upcoming articles.
Let us start with difference between image and object from a computer-vision context.

What we see above is an image. We can see 3 objects inside – 1 cat and 2 dogs. If we wish, we can count the ribbon on head of left one as 4th object.
There are mainly 2 types of images – Red Green Blue (RGB) scale and gray scale (black & white) as illustrated below.


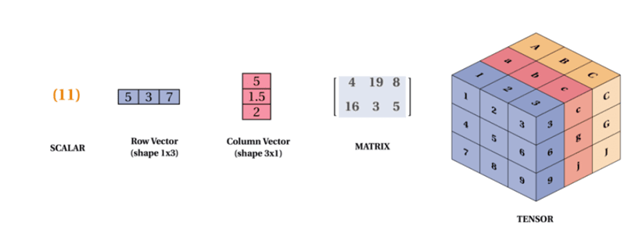
Unlike us, computers understand only language of mathematics. Hence we convert images to tensors using libraries like Python Imaging Libraries (PIL). You can imagine tensors as n-dimensional matrices as illustrated below.
So, how computers detect and classify objects ? One way in which computers achieve this is via neural networks. Below is a high-level representation of how neural networks work.

Lets us go step-by-step to understand the above flow. Please notice that lightning effect is going back and forth.
First let us understand the forward flow.
- Input images are converted to tensors and fed to neural network.
- These are then broken down to basic channels with a mathematical operation called convolution. You can imagine this like dismantling an assembled lego board to smaller pieces.
- We will then continue apply convolutions to our basic channels. This way we will reconstruct edges & gradients, textures & patterns, parts of objects and objects. These will happen inside hidden layers.
- In above diagram, we have shown only 1 hidden layer, but that won’t be the case in real models. We will have multiple hidden layers before final output layer. Towards the final hidden layers we can expect channels resembling original object that we are attempting to classify. (As shown below).
- Next we will flatten the output of final convolution layers and feed it to Softmax activation function. Dimension of flattened array will be same as number of classes. For example, if we want to predict digits (0-9), then softmax input will a 10 member array.
- Softmax will give us the probability of input image belonging to each class. Eg: cat : 0.05, dog : 0.92, horse : 0.03. Here predicted class is dog.

The steps I mentioned above comprise a forward pass. Next let us inspect what happens backward. We call this backward propagation. This is how model learns and improves.
- After prediction, each layer will receive feedback from its preceding layer. Feedback will be in the form of losses incurred at each layer during prediction.
- Aim of algorithm is to arrive at optimal loss. We call this as local minima.
- Based on the feedback, network will adjust itself so that convolutions will give better results when next forward pass happens.
- When next forward pass happens, loss will come down. Again, we will do backprop, network will continue to adjust and process repeats.
- This forward pass followed by back prop will keep happening the number of times we choose to train our model. We call it epochs.
Hope this gave you a high-level understanding on how a deep learning neural network detects objects. In future weeks, I will delve deep into the points mentioned above.

Nice explanation
LikeLiked by 1 person